1. 원시값의 메서드
원시값은 객체가 아니기 때문에 프로퍼티나 메서드가 있을 수 없다. 하지만 toUpperCase와 같이 원시값에 적용되는 메서드가 분명히 있다. 문자열의 length와 같은 프로퍼티도 있다. 어떻게 된 걸까?
1.1. 원시값 래퍼 객체
JS의 원시값에 메서드를 사용하기 위해 이런 방식이 사용된다.
먼저 원시값은 원시값 그대로 형태를 유지한다. 그리고 원시값이 메서드나 프로퍼티에 접근하려고 할 시 추가 기능을 제공하는 특수한 임시 래퍼 객체를 만들어 주고 메서드/프로퍼티 접근을 적용한다. 객체는 그 접근이 끝나면 삭제된다.
즉 원시값의 메서드나 프로퍼티에 접근하게 되면 원시값은 임시로 객체처럼 작동한다. 따라서 원시값의 프로퍼티 접근도 시도할 수 있다.
a="test";
console.log(a.foo); //undefinedJS 엔진들은 이런 래퍼 객체 최적화에 신경을 쓰기 때문에 이를 사용하는 건 그렇게 많은 자원을 필요로 하지 않는다.
1.2. 래퍼 객체 생성자
래퍼 객체를 직접 만들 수도 있다. Number, Boolean, String과 같은 문법을 생성자 함수로 사용하면 된다. 그렇게 하면 각 원시값의 래퍼 객체가 생긴다.
그러나 이를 사용하는 것은 좋지 않다. 원시값으로 취급되어야 하는 값이 객체로 취급되는 건 혼동을 부를 수 있기 때문이다. 예를 들어 new Number(0)으로 값을 생성한다면 0값을 가진 Number 임시 객체가 생성될 것이다.
그런데 이를 논리 평가에 사용한다면, 객체는 언제나 논리 평가 시 참이기 때문에 Number{0}은 참이 될 것이다. 하지만 숫자 0은 일반적으로 false로 평가되는 게 맞으므로 원치 않는 동작이 생길 수 있다.
2. 숫자형
JS에서 숫자는 BigInt를 제외하고 IEEE-754 형식으로 저장된다.
2.1. 진법 표현
일반적으로 JS에서 모든 수는 10진수로 취급된다. 1e9와 같이 과학적 표기법도 가능하다.
그러나 16진수, 8진수, 2진수도 지원하는데 이는 각각 0x, 0o, 0b라는 접두사로 표현 가능하다. 하지만 비교 연산자를 사용할 시 같은 수 판단은 진수에 상관없이 이루어진다. 예를 들어 0b11===3은 true이다.
만약 다른 진법을 사용해서 정수를 쓰고 싶다면 parseInt를 써야 한다.
2.1.1. toString(base)로 진법 다루기
num.toString(base)는 num을 base진법으로 표현한 후 문자열로 변환해서 반환해 준다. base는 2~36까지 쓸 수 있다.
let a=33;
console.log(a.toString(16)); //212.2. 부정확한 계산
JS에서 숫자는 BigInt를 제외하면 내부적으로 IEEE-754 형식으로 표현된다. 정확히 64비트에 저장되는데 이때 52비트가 숫자를 저장하고 11비트는 소수점 위치를, 1비트는 부호를 저장한다.
그런데 만약 너무 큰 수가 저장되면 64비트 공간이 넘쳐서 Infinity로 처리되기도 한다. 예를 들어 1e500과 같은 수를 출력해 보면 Infinity가 출력된다.
또한 유명한 예시인 0.1+0.2===0.3이 false인 것도 IEEE754 저장 방식의 문제이다. 0.1, 0.2 와 같은 소수를 2진법의 IEEE754 형식으로 정확하게 표현할 수 없기 때문이다.
이를 해결하는 방법 중 하나는 toFixed를 사용하는 것이다. 이때 toFixed는 문자열을 반환하므로 숫자형 변환을 위해 단항 연산자 +를 사용한다.
let res=0.1+0.2;
console.log(+res.toFixed(2)); //0.3비슷한 정밀도 손실 예시로 너무 큰 수를 표현하게 되면 유효숫자가 손실되어 부정확하게 표현되는 것이 있다.
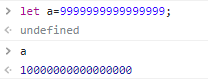
2.3. 숫자형 관련 메서드 몇개
Infinity, -Infinity, NaN은 숫자형에 속한다. 그러나 일반적인 숫자는 아니기 때문에 그것인지 확인하는 함수도 존재한다. isNaN과 isFinite이다.
이때 isNaN이 필요한 이유는 NaN이 다른 모든 값과 같지 않기 때문이다. 심지어 자기 자신과도 같지 않다.
alert(NaN === NaN) //falseisFinite는 인수로 받은 숫자가 NaN, Infinity, -Infinity가 아닌 일반적인 숫자일 경우 true를 반환한다.
또한 불가능할 때까지 문자열에서 숫자를 읽는 parseInt, parseFloat 함수가 존재한다. 문자열을 읽는 도중 숫자가 아닌 게 나오면 그때까지 수집된 숫자를 반환한다.
console.log(parseInt('120px')); //120
console.log(parseFloat('12.5rem')); //12.5parseInt("a")와 같이 읽을 수 있는 숫자가 없을 경우 NaN을 반환한다. 그리고 parseInt의 2번째 인수에 2~36을 넘겨주면 파싱할 때 사용할 진수를 사용할 수 있다.
console.log(parseInt('0xff', 16));2.4. Object.is
Object.is는 값을 비교할 때 사용하는 메서드인데 ===과 다른 결과를 반환하는 2가지 케이스가 있다.
NaN===NaN은 false지만Object.is(NaN, NaN)은 true0===-0은 true지만Object.is(0, -0)는 false
Object.is의 비교방식을 SameValue라고 한다.
2.5. 그 외 메서드
2.5.1. Math.random()
0~1 사이의 난수를 반환한다. 여기서 반환되는 난수에 1은 제외이다.
2.5.2. Math.max, Math.min
인수로 받은 수들 중 최댓값, 최솟값을 반환한다. 인수 중 숫자가 아닌 문자열이 있으면 숫자로 반환되고 이게 실패하면 NaN이 반환된다.
2.5.3. Math.pow(n, p)
n을 p제곱한 값을 반환한다. 이때 실수 제곱도 가능하다.
3. 문자열
JS는 char형 같은 게 없다. 문자열뿐이다. 그리고 이 문자열은 무조건 UTF16 인코딩을 따른다.
문자열을 선언하는 방법은 큰따옴표나 작은따옴표를 사용하는 방법이 하나 있다. 그리고 백틱을 사용하여 템플릿 리터럴을 사용하는 방법이 있는데 이는 이 글에 정리해 놓았다.
이때 주의할 점은 문자열은 불변하는 값이라는 것이다. word[0]='a'처럼 변경을 시도하면 에러가 발생한다.
3.1. 유니코드 표현
\를 사용하여 이스케이프 문자를 표현할 수 있다는 건 유명하다. 그런데 자바스크립트에선 이를 이용해 유니코드 기호도 표현할 수 있다.
\uXXXX의 XXXX위치에 UTF-16 인코딩의 16진수 코드를 넣으면 된다. UTF-32 의 긴 유니코드를 사용하고 싶다면 \u{XX..XX}를 사용하면 된다.
console.log("\u00A9");
console.log("\u{1F60D}");3.2. 프로퍼티와 메서드
문자열은 원시값이지만 앞에서 살펴봤다시피 임시 래퍼 객체를 통해 프로퍼티와 메서드 접근이 가능하다.
3.2.1. length
length 프로퍼티는 문자열의 길이를 저장한다. str.length처럼 사용 가능하다.
3.2.2. charAt
문자열 내 특정 인덱스의 글자에 접근하려면 대괄호 인덱싱을 이용할 수 있지만 charAt메서드를 사용할 수도 있다. 두 방법의 차이는, 접근하려는 위치에 글자가 없을 경우 대괄호 방식은 undefined를 반환하지만 charAt은 빈 문자열을 반환한다는 것이다.
let word="witch";
console.log(word[10]); //undefined
console.log(word.charAt(10)); //빈 문자열3.2.3. 문자열 순회
for..of를 이용해서 문자열을 구성하는 글자를 한 글자씩 순회하며 작업할 수 있다.
for(let ch of word){
console.log(ch);
}3.2.4. 대문자, 소문자 변경
toUpperCase는 문자열의 모든 알파벳을 대문자로 바꾼 문자열을 리턴해 주고 toLowerCase는 모든 알파벳을 소문자로 바꾼 문자열을 리턴한다.
3.2.5. 부분 문자열 찾기
indexOf메서드를 사용하면 부분 문자열을 찾을 수 있다. word.indexOf(substr, pos)는 word 문자열에서 substr을 찾아서 그 시작 위치(인덱스)를 반환한다. 만약 찾지 못하면 -1을 반환한다.
이때 두번째 인수 pos는 선택적 인수인데 만약 두번째 인수를 전달하지 않으면 주어진 문자열의 첫 인덱스부터 탐색을 시작한다. pos인수를 넘겨주면 해당 pos 인덱스부터 탐색이 시작된다.
같은 기능이지만 문자열 끝에서부터 substr을 찾는 메서드로 lastIndexOf가 있다.
단 주의할 점은, 문자열을 찾았는지 판단할 때 0과 비교하면 안 된다는 점이다. indexOf가 탐색에 성공해서 반환한 값이 0일 수 있기 때문이다.
let word="witch";
// w를 찾았지만 반환값이 0이므로 아무것도 출력되지 않음
if(word.indexOf('w')){
console.log("w is found");
}이런 경우 indexOf 리턴값을 -1과 비교해야 한다. 다음 코드는 정상적으로 작동한다.
let word="witch";
if(word.indexOf('w')!==-1){
console.log("w is found");
}부분 문자열의 포함 여부를 알아내는 메서드로 str.includes(substr, pos)가 있다. substr의 존재여부에 따라 true, false를 반환한다. 2번째 인수 pos의 용도도 indexOf에서와 같다.
또한 startsWith, endsWith로 문자열이 특정 문자열로 시작하거나 끝나는지를 판단할 수도 있다.
3.2.6. 부분 문자열 추출
문자열의 일부를 추출하는 메서드는 3가지가 있다.
str.slice는 파이썬의 slicing과 같이 start~end인덱스의(end는 미포함) 문자열을 반환한다. 만약 2번째 end 인수가 생략되면 start부터 끝까지를 반환한다.
또한 음수 인수를 넘길 수도 있는데 이 경우 문자열 끝에서부터 인덱스 카운팅을 시작한다. 즉 맨 마지막 문자가 -1인덱스가 되는 것이다.
let word="witch_work";
console.log(word.slice(1,5)); //itch
console.log(word.slice(5)); //_work
console.log(word.slice(3,-4)); //ch_
console.log(word.slice(4,3)); // 빈 문자열slice는 만약 start가 end와 같거나 더 크면 빈 문자열을 반환한다.
substring은 slice와 같은 기능을 하는 메서드지만 음수 인수를 허용하지 않는다. 음수 인수를 넣을 경우 0으로 처리된다. 그리고 start가 end보다 커도 s~e 사이의 문자열을 잘 추출한다.
let word="witch_work";
// witc 가 출력된다.
// 음수 인수가 0으로 처리되어 substring(4,0)이 되고 따라서 0~4 사이의 문자열이 추출되기 때문
console.log(word.substring(4,-1));이렇게 인덱스를 이용하는 것 대신 길이를 이용하는 방식도 있다. str.substr(start, length)는 start인덱스부터 시작해 length개의 문자열을 추출한다. 단 이 substr은 브라우저 전용 기능이므로 브라우저 외 환경에서는 제대로 동작하지 않을 수 있다.
그리고 slice가 음수 인수가 허용되어 좀더 유연하므로 slice를 쓰는 게 substring보다 일반적으로 더 좋은 선택이다.
3.3. 문자열 비교
JS에서 문자열은 모두 UTF-16으로 인코딩되고 따라서 모든 글자가 숫자 형식 코드와 매칭된다. 이 코드는 str의 특정 인덱스에 위치한 문자의 코드를 알아내는 메서드 str.codePointAt(index)로 알아낼 수 있다. 반대로 String.fromCodePoint(code)로 특정 숫자코드에 대응하는 글자를 만들어 줄 수도 있다.
아무튼 JS는 문자열을 비교할 때 이 숫자 코드를 이용해서 비교한다. 각 문자열의 첫 인덱스부터 한 글자씩 비교해 가면서 숫자 코드가 더 큰 문자가 나온 문자열이 더 크다고 판단하는 것이다.
따라서 단순히 문자열에 비교 연산자를 쓰면 소문자가 대문자보다 무조건 크게 나오는 등의 문제가 있다. 제대로 비교하기 위해서는 국제화 관련 표준인 ECMA-402를 통해 문자열을 비교하는 str.localeCompare(str2)를 써야 한다.
str이 str2보다 작으면 음수, 같으면 0, str이 str2보다 크면 양수를 반환한다.
console.log("ABC".localeCompare("abb")); //1
console.log("ABC">"abb"); //false위의 결과를 보면 단순 비교를 했을 경우 대문자가 숫자코드가 작으므로 더 작다고 판단되었지만 localeCompare에서는 ABC가 abb보다 더 크다는, 일반적인 알파벳에 기반한 비교를 잘 해준 것을 볼 수 있다.
4. 배열
4.1. 배열 생성
배열은 대괄호를 쓰거나 생성자를 사용해 만든다.
let arr = new Array();
let arr2 = [];4.2. 배열 순회
배열을 순회할 때는 for문을 쓰는 게 일반적이다. 이때 3가지 선택지가 있다. 인덱스를 사용해 순회하는 건 가장 기본적인 방법이다.
let members = ["고주형", "전민지", "장소원"];
for (let i=0;i<members.length;i++) {
console.log(members[i]);
}for-of문을 쓰는 방법도 있다. 이 방법은 배열의 요소를 순회하면서 요소를 변수에 할당해주는 방식이다. 배열의 인덱스 말고 값만이 필요할 때 사용하면 좋다.
let members = ["고주형", "전민지", "장소원"];
for (let member of members) {
console.log(member);
}for-in문을 사용할 수도 있다. 그러나 for-in문은 객체를 순회할 때 사용하는 것이 일반적이며 키가 숫자가 아닌 프로퍼티와 메서드를 가지는 유사 배열 객체의 경우 원치 않는 프로퍼티까지 순회하는 결과가 나올 수 있다.
let members = ["고주형", "전민지", "장소원"];
members.foo = "김성현";
// members의 foo도 순회에 포함된다
for (let name in members) {
console.log(members[name]);
}
// members의 foo는 순회에 포함되지 않는다
for (let name of members) {
console.log(name);
}게다가 for-in은 객체에 사용하는 것에 최적화되어 있어 배열에 for-of를 쓰는 것보다는 느리다.
4.3. length
배열의 length는 배열 내의 실제 요소 개수를 세는 게 아니라 배열 내의 가장 큰 인덱스에 1을 더한 값이다.
let test = [];
test[1000] = 1;
console.log(test.length);
// 배열에 요소는 실제로는 하나뿐인데 length는 1001또한 배열 length에는 쓰기도 가능하다. 이때 length가 줄어들면 배열의 뒤쪽 요소가 삭제된다. 기존 length보다 더 큰 length를 지정하면 배열 뒤쪽엔 빈 공간이 채워진다.
let test = [1, 2, 3];
// [1, 2, 3] 3
console.log(test, test.length);
test.length = 5;
// [1, 2, 3, empty × 2] 5
console.log(test, test.length);
test.length = 2;
// [1, 2] 2. 배열이 잘렸다!
console.log(test, test.length);4.4. 배열 메서드
잘 모르고 있던 메서드만 적는다.
4.4.1. splice
splice는 배열의 요소를 삭제하거나 추가할 때 사용한다. 첫 번째 인수는 시작 인덱스, 두 번째 인수는 삭제할 요소 개수, 세 번째 인수부터는 추가할 요소를 나열한다.
arr.splice(index[, deleteCount, elem1, ..., elemN])이때 추가할 요소는 index번째(0-base) 원소의 앞에 추가된다. 즉, index번째 원소는 뒤로 밀려난다. arr.splice(0, 0, 1) 과 같은 경우 배열의 첫 번째에 삽입되어야 하는 것을 생각하면 당연하다.
여기에는 음수 인덱스도 사용할 수 있다.
4.4.2. forEach
forEach는 배열의 요소를 순회하면서 각 요소에 대해 함수를 실행한다. forEach는 반환값이 없다.(정확히는 undefined를 반환한다.)
let arr = [1, 2, 3, 4, 5];
arr.forEach((item, index) => {
console.log(item, index);
});4.4.3. indexOf, lastIndexOf, includes
문자열의 같은 메서드와 같은 기능을 한다.
arr.indexOf(item, from) // from부터 item을 찾는다. 못 찾으면 -1
arr.lastIndexOf(item, from) // from부터 item을 뒤에서부터 찾는다. 못 찾으면 -1
arr.includes(item, from) // from부터 item이 있는지 검색. 못 찾으면 false4.4.4. find, findIndex
find는 배열의 요소를 순회하면서 조건에 맞는 첫 번째 요소를 반환한다. findIndex는 조건에 맞는 첫 번째 요소의 인덱스를 반환한다.
만약 조건에 맞는 요소가 없으면 find는 undefined, findIndex는 -1을 반환한다.
4.4.5. map
map은 배열의 요소를 순회하면서 각 요소에 대해 함수를 실행한 결과를 모아 새로운 배열을 만들어서 리턴해 준다.
let arr = [1, 2, 3, 4, 5];
let res = arr.map((item) => item + 10);
// 11,12,13,14,15
console.log(res);4.4.6. reduce, reduceRight
reduce는 배열의 전체 원소들을 기반으로 값을 하나 도출할 때 사용한다. 다음과 같은 형태로 사용된다.
arr.reduce(function(accumulator, item, index, array) {
// ...
}, [initial]);reduce는 배열의 첫 번째 원소부터 마지막 원소까지 순회하면서 accumulator에 값을 누적시킨다. accumulator는 초기값으로 initial을 사용할 수도 있고, 사용하지 않을 경우 배열의 첫 번째 원소를 사용한다.
reduce에 쓰이는 함수의 인수들은 다음과 같은 의미가 있다. accumulator는 이전 함수 호출의 결과인 누적 값, item은 현재 배열의 원소, index는 현재 배열의 인덱스, array는 배열 자체를 의미한다.
예를 들어 reduce를 이용해 배열 요소 전체의 합을 구할 수 있다.
let arr = [1, 2, 3, 4, 5];
// initial누적값을 정하지 않았으므로 배열의 첫 번째 원소 1이 첫 누적값으로 사용된다
let res = arr.reduce((s, current) => s + current);
// 15
console.log(res);단 이렇게 초기값을 명시하지 않을 경우, 만약 배열이 비어 있다면 문제가 생긴다. 첫번째 원소가 없기 때문이다. 따라서 초기값을 명시해 주는 것이 안전하다. 다음과 같이 말이다.
let res = arr.reduce((s, current) => s + current, 0);reduceRight는 reduce와 동일한 기능을 하지만, 배열의 끝에서부터 시작한다.
4.4.7. isArray
해당 원소가 배열이면 true, 아니면 false를 반환한다.
4.4.8. thisArg
배열 메서드들은 모두 thisArg라는 인수를 받을 수 있다. thisArg는 메서드 내부에서 this로 사용할 객체를 지정한다. thisArg를 사용하지 않으면 함수 내부에서 this는 undefined가 된다(브라우저 환경에선 전역 윈도우 객체).
let numberFilter = {
min: 18,
max: 99,
filter(value) {
if (value < this.min || value > this.max) {
return false;
}
return true;
},
};
let ages = [12, 18, 20, 1, 100, 90, 14];
// numberFilter.filter의 this로 numberFilter 객체를 사용한다고 지정
let filtered = ages.filter(numberFilter.filter, numberFilter);
console.log(filtered);5. 이터러블
객체를 이터러블로 만들면 어떤 객체든 for..of로 순회할 수 있다. 객체에 for..of가 호출되면 다음과 같은 일이 일어나기 때문이다.
- 객체의 Symbol.iterator 메서드를 호출한다. 이때 Symbol.iterator는 next 메서드를 갖는 이터레이터 객체를 반환해야 한다.
- for..of는 다음 값이 필요할 때마다 이터레이터 객체의 next 메서드를 호출한다. 이때 next 메서드는 value와 done 프로퍼티를 갖는 객체를 반환해야 한다.
- next 메서드가 반환하는 객체의 done 프로퍼티가 true가 될 때까지 for..of는 반복한다.
객체의 Symbol.iterator의 구조는 다음과 같이 이루어진다.
객체[Symbol.iterator] = function(){
return {
// next 메서드가 구현되어 있는 객체
next(){
if(순회할 값이 더 있으면){
return {done: false, value: 순회할 다음 값}
} else {
return {done: true}
}
}
}
}혹은 next 메서드를 아예 객체 자체에 구현해 놓은 다음 Symbol.iterator에서는 객체 자신을 반환해 주도록 하는 것도 가능하다.
let obj={
[Symbol.iterator]: function(){
// for..of가 시작돨 때의 초기 조건 설정
return this;
},
next(){
if(순회할 값이 더 있으면){
return {done: false, value: 순회할 다음 값}
} else {
return {done: true}
}
}
}단 위와 같은 방식의 단점은 2개의 for..of 반복문을 동시에 쓸 수 없다는 점이다. 이터레이터가 객체 자신 그 하나뿐이므로 반복의 진행 상태를 공유하기 때문이다.
이터러블을 만들면 관심사의 분리가 가능해진다. next메서드는 이터레이터 객체에 맡기고 반복하는 객체는 반복의 메커니즘에는 신경쓸 필요가 없어진다.
5.1. 이터러블 직접 호출
이터레이터를 직접 호출하는 것도 가능하다. 단 잘 쓰이는 것은 아니다.
let it=obj[Symbol.iterator]();
while(1){
let result=it.next();
if(result.done) break;
console.log(result.value);
}5.2. 이터러블과 배열
이터러블은 Symbol.iterator 메서드를 가져서 반복 가능한 객체이다. 유사 배열 객체와는 다르다. 유사 배열 객체는 인덱스와 length 프로퍼티를 가지고 있는 객체이다.
인덱스와 length가 있지만 Symbol.iterator가 없는 유사 배열 객체도 있다.
// 인덱스, length 프로퍼티가 있지만 Symbol.iterator가 없어서 이터러블은 아닌 유사 배열 객체
let arrayLike={
0: 'hello',
1: 'world',
length: 2
}5.3. Array.from
Array.from 메서드는 이터러블이나 유사 배열을 진짜 배열로 바꿔서 반환해 준다. 이러면 배열 메서드도 쓸 수 있게 된다.
let arr = {
0: "witch",
1: "work",
length: 2,
};
let arr2 = Array.from(arr);
arr2.pop();
console.log(arr2); // ['witch']Array.from은 넘겨받은 객체가 이터러블이나 유사 배열이면 이를 배열로 변환해 준다. 그리고 이 함수는 선택적인 인수가 있다.
Array.from(obj, [mapFn, thisArg])mapFn 함수를 지정하면 변환한 배열을 추가하기 전에 각 요소에 mapFn을 적용한다. 그리고 thisArg를 지정하면 mapFn을 호출할 때 this로 사용할 객체를 지정할 수 있다.